Kubernetes, cloud-native infra, and the bits the docs leave out.
Three ways to deploy Helm charts on Kubernetes, and when each one breaks
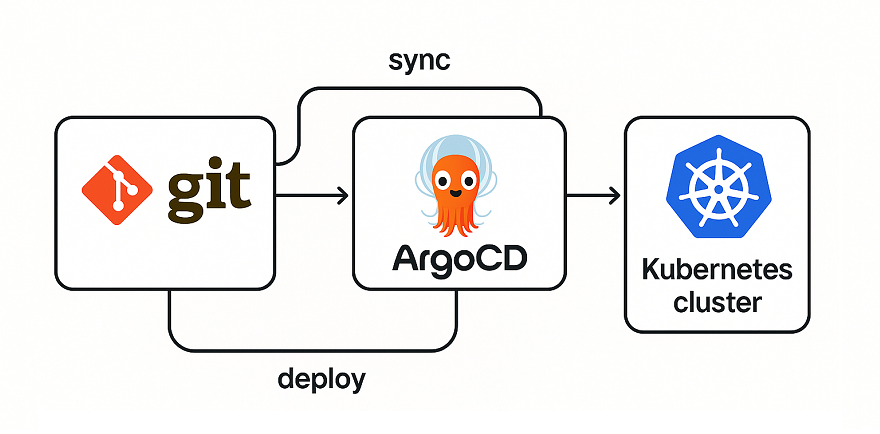
Most teams deploy Helm charts the way they did on day one, and never revisit it until it hurts. The pipeline that ran helm upgrade --install against a staging cluster two years ago is still the thing shipping production today, and nobody questions it because it works. Right up until it doesn’t. The part nobody frames clearly is that Helm itself is just templating. It takes values and a chart and renders Kubernetes manifests. That rendering step is identical no matter what you do. The real question is how the rendered output lands on the cluster and how it stays there. There are three answers I have run in production, and each one is correct in a specific place and a liability everywhere else. ...
MLflow on Kubernetes: why the community chart is not enough
The community MLflow chart is great for a demo and useless for production. It knows nothing about your Key Vault, your Workload Identity, your Traefik ingress, or your certs. Here is the layered Helm pattern I run instead, where the open source chart stays untouched and your cloud specifics live in a thin layer on top. Plus the one missing package that breaks Workload Identity on day one.
Taming Azure AI Foundry with LiteLLM: budgets and key rotation
Azure AI Foundry is amazing until you have to manage it for more than one team. Here is how LiteLLM became the gateway that fixed my key sprawl, capped everyone’s spend, and turned key rotation from a fire drill into a thirty second job.